When working with Longhorn, you may encounter two different VolumeAttachment resources with similar names: Kubernetes VolumeAttachment (storage.k8s.io/v1) and Longhorn VolumeAttachment (longhorn.io/v1beta2). This often causes confusion about why both exist, when each is created, whether they always appear together, and which one to check when troubleshooting. This document clarifies their distinct roles, shows how they work together (and when they don't), and provides real-world examples to help you identify attachment sources and effectively troubleshoot volume attachment issues.
For additional context, see the official documentation at https://longhorn.io/docs/latest/advanced-resources/volumeattachment/
note
The observations and analysis in this document are based on Longhorn latest 1.10.x branch.
Workflow: How K8s and Longhorn VolumeAttachments Work Together
When a Pod requires a Longhorn volume, two separate VolumeAttachment resources work together to complete the attachment process. The Kubernetes VolumeAttachment represents the CSI standard attachment request, while the Longhorn VolumeAttachment manages the actual attachment orchestration with ticket-based coordination.
The following diagram illustrates the complete flow from Pod scheduling to successful volume attachment:
┌─────────────────────────────────────────────────────────────┐
│ Pod Scheduled to Node │
└─────────────────────┬───────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────┐
│ Kubernetes Attach/Detach Controller │
│ Creates K8s VolumeAttachment │
│ APIVersion: storage.k8s.io/v1 │
│ Spec: │
│ Attacher: driver.longhorn.io │
│ NodeName: worker-node-1 │
│ Source.PersistentVolumeName: pvc-xxx │
└─────────────────────┬───────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────┐
│ CSI External-Attacher (Longhorn) │
│ Watches K8s VolumeAttachment │
└─────────────────────┬───────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────┐
│ Longhorn CSI Plugin │
│ Calls ControllerPublishVolume() │
└─────────────────────┬───────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────┐
│ Longhorn Manager API │
│ Creates/Updates Longhorn VolumeAttachment │
│ APIVersion: longhorn.io/v1beta2 │
│ Spec: │
│ Volume: my-volume │
│ AttachmentTickets: │
│ csi-attacher-<hash>: │
│ ID: <pod-id> │
│ Type: csi-attacher │
│ NodeID: worker-node-1 │
│ Parameters: {...} │
└─────────────────────┬───────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────┐
│ Longhorn VolumeAttachment Controller │
│ 1. Evaluates all attachment tickets │
│ 2. Selects appropriate ticket to satisfy │
│ 3. Updates Volume.Spec.NodeID = worker-node-1 │
└─────────────────────┬───────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────┐
│ Longhorn Volume Controller │
│ Performs actual volume attachment operation │
└─────────────────────┬───────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────┐
│ Longhorn VolumeAttachment Controller │
│ Updates ticket status: Satisfied = true │
└─────────────────────┬───────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────┐
│ Longhorn CSI Plugin │
│ Returns attach success to external-attacher │
└─────────────────────┬───────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────┐
│ CSI External-Attacher │
│ Updates K8s VolumeAttachment.Status.Attached = true │
└─────────────────────────────────────────────────────────────┘
The resulting Longhorn VolumeAttachment YAML:
apiVersion: longhorn.io/v1beta2
kind: VolumeAttachment
metadata:
name: pvc-0b9c8d59-0ae8-413c-8bc5-af32b932b8ab
namespace: longhorn-system
labels:
longhornvolume: pvc-0b9c8d59-0ae8-413c-8bc5-af32b932b8ab
spec:
volume: pvc-0b9c8d59-0ae8-413c-8bc5-af32b932b8ab
attachmentTickets:
# This CSI ticket was triggered by K8s VolumeAttachment (Pod binding)
csi-3d3120f43480db87c91a6902d670c35899917c03f9f6f81db7bf26d9d66e45ec:
id: csi-3d3120f43480db87c91a6902d670c35899917c03f9f6f81db7bf26d9d66e45ec
type: csi-attacher
nodeID: harvester-node-1
parameters:
disableFrontend: "false"
status:
attachmentTicketStatuses:
csi-3d3120f43480db87c91a6902d670c35899917c03f9f6f81db7bf26d9d66e45ec:
id: csi-3d3120f43480db87c91a6902d670c35899917c03f9f6f81db7bf26d9d66e45ec
satisfied: true # Volume successfully attached
conditions:
- type: Satisfied
status: "True"
Notice the csi-attacher ticket type - this confirms the attachment was triggered by Kubernetes VolumeAttachment through the CSI flow, not by Longhorn internal operations.
Trigger Points
Understanding when each VolumeAttachment is created or modified is crucial for troubleshooting attachment issues:
K8s VolumeAttachment Creation: Triggered when Pod is scheduled to a node requiring a PVC
- Managed by Kubernetes Attach/Detach (AD) Controller
- One VolumeAttachment per PV-node combination
- Represents Kubernetes' intent to attach the volume
Longhorn VolumeAttachment Ticket Addition: Triggered by various Longhorn components based on operation needs:
CSIAttacher- when CSI ControllerPublishVolume is calledSnapshotController- when creating snapshots of volumesBackupController- when backing up volumesLonghornAPI- when users manually attach volumes via Longhorn UIVolumeCloneController- when managing source volume during cloneVolumeRestoreController- when restoring data from backupsVolumeExpansionController- when expanding volume sizeShareManagerController- for RWX volume sharingSalvageController- for volume salvage operations
Attachment Ticket Priority and Coordination
When multiple operations require volume attachment simultaneously, Longhorn uses a ticket-based priority system to coordinate access intelligently. This ensures critical operations take precedence while allowing background tasks to coexist when possible.
How Priority Works
Each ticket type has an assigned priority level that determines selection order when the volume is detached:
- Priority 2000 (Highest):
VolumeRestoreControllerVolumeExpansionController
- Priority 1000:
LonghornAPI
- Priority 900:
CSIAttacherShareManagerControllerSalvageController
- Priority 800 (Lowest):
BackupControllerSnapshotControllerVolumeCloneControllerVolumeEvictionController
When the volume is detached, the ticket with the highest priority is selected for attachment. If multiple tickets share the same priority, the first one (sorted by ID) is chosen.
note
For ReadWriteMany (RWX) Filesystem mode volumes, CSIAttacher tickets are ignored during ticket selection and detachment decisions. Only the ShareManagerController ticket is considered, as it manages the centralized sharing mechanism for RWX access. Individual CSI attacher tickets from Pods are summarized and handled by the Share Manager, not directly by the VolumeAttachment Controller.
Interruption Mechanism
Priority levels alone don't tell the complete story. Longhorn also implements an interruption mechanism to handle cases where request arrives while the volume is already attached to a different node.
Interruptible operations (can be interrupted):
BackupControllerSnapshotControllerVolumeCloneController- clone operations, but only when the volume is inVolumeCloneStateCopyCompletedAwaitingHealthystate
note
The VolumeCloneController is only interruptible in a specific state. During the data copy phase, clone operations cannot be interrupted. Interruption is only allowed after the copy completes and the volume is waiting to become healthy, preventing data corruption during active copy operations.
Workload operations (can trigger interruption):
CSIAttacher- Pod workloads requiring the volume on a different nodeLonghornAPI- manual attachment requests via UI/APIShareManagerController- RWX volume sharing operations
The interruption only occurs when:
- The volume's currently attached node has only interruptible tickets
- A different node has a workload ticket requesting the volume
note
Interruption is based on ticket type classification, not priority numbers. Priority numbers only affect the selection order during the attachment phase when the volume is detached.
This design ensures background operations never block workload rescheduling, while protecting active workloads from being interrupted by other background tasks.
Real-World Scenarios
Scenario 1: Backup During Active Pod Usage
- Pod is running on node-A with a
CSIAttacherticket BackupControllercreates a ticket for node-A (same node)- Both tickets coexist peacefully - backup runs alongside the Pod
- CSI attachment and backup execution use the engine on the same node, avoiding a node transition.
Scenario 2: Backup Interrupted by Pod Workload
BackupControlleris running on node-A (only ticket present)- A Pod requiring this volume is scheduled to node-B,
CSIAttachercreates a ticket for node-B - VolumeAttachment Controller detects: interruptible ticket on node-A, workload ticket on node-B
- Volume detaches from node-A (backup interrupted), attaches to node-B (csi attacher)
- Backup will retry later automatically
Scenario 3: Detached Volume Snapshot
- Volume is detached,
SnapshotControllercreates a ticket - Volume attaches temporarily for snapshot creation
- After snapshot completes, ticket is removed
- Volume auto-detaches if no other tickets exist
Usage Examples
The following examples demonstrate how VolumeAttachment resources behave in common scenarios. Each example shows the complete YAML resource state at different stages, helping you understand what to look for when troubleshooting or monitoring Longhorn operations.
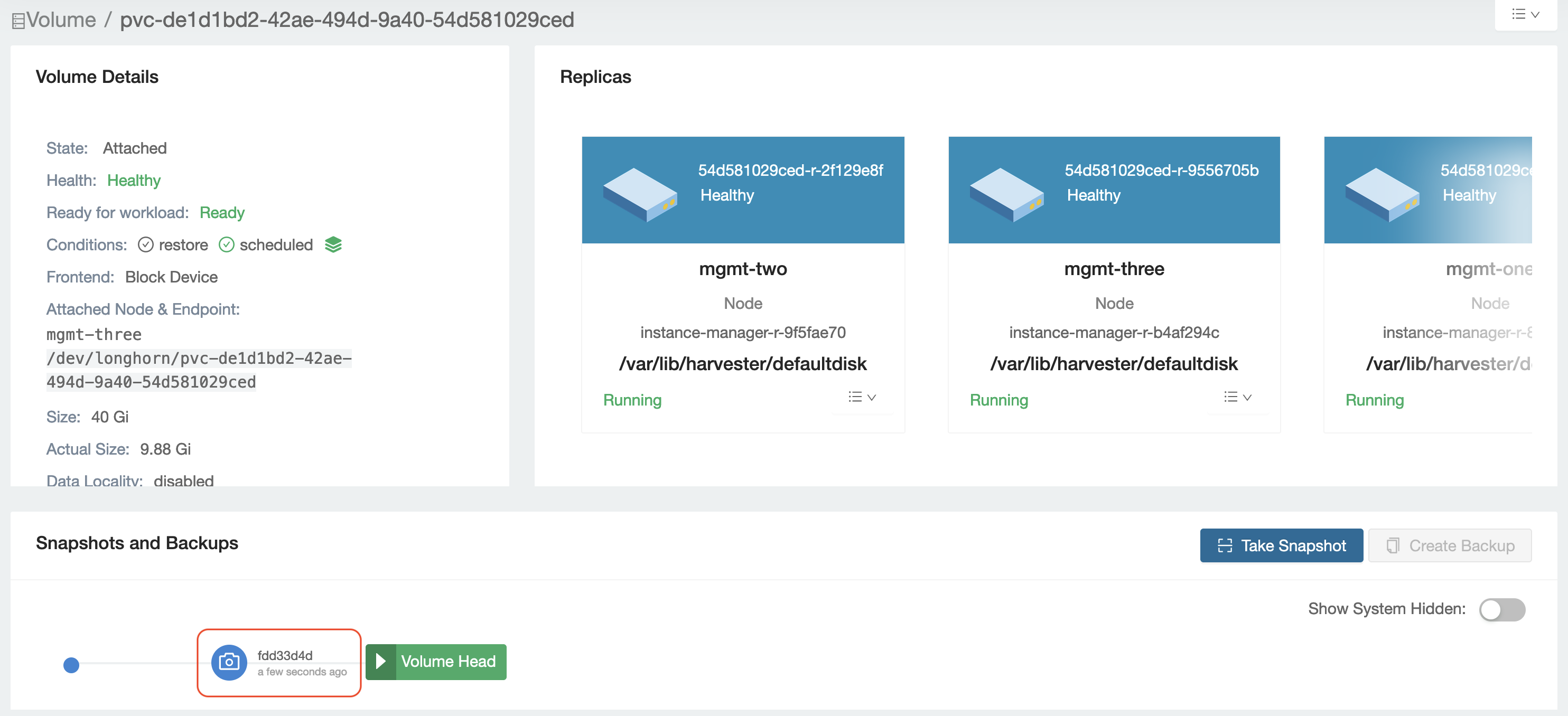
Example 1: VolumeSnapshot Creation (Longhorn VolumeAttachment Only)
VolumeSnapshot operations use only Longhorn VolumeAttachment without involving Kubernetes VolumeAttachment. This demonstrates that Longhorn VolumeAttachment can operate independently for internal operations.
┌─────────────────────────────────────────────────────────────┐
│ User Creates VolumeSnapshot via kubectl │
│ kubectl apply -f volumesnapshot.yaml │
└─────────────────────┬───────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────┐
│ Longhorn Snapshot Controller │
│ Detects new VolumeSnapshot resource │
└─────────────────────┬───────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────┐
│ Snapshot Controller Checks Volume State │
│ If Volume is detached → needs attachment for snapshot │
└─────────────────────┬───────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────┐
│ Snapshot Controller Creates Attachment Ticket │
│ Updates Longhorn VolumeAttachment: │
│ AttachmentTickets: │
│ snapshot-<snapshot-name>: │
│ Type: snapshot-controller │
│ NodeID: <volume-owner-node> │
│ Parameters: {disableFrontend: "false"} │
│ │
│ ❌ No K8s VolumeAttachment created │
└─────────────────────┬───────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────┐
│ Longhorn VolumeAttachment Controller │
│ Selects snapshot ticket → Updates Volume.Spec.NodeID │
└─────────────────────┬───────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────┐
│ Longhorn Volume Controller │
│ Attaches volume → Starts Engine │
└─────────────────────┬───────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────┐
│ Snapshot Controller │
│ Engine running → Creates snapshot via Engine API │
│ Snapshot complete → Removes attachment ticket │
└─────────────────────┬───────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────┐
│ Volume May Auto-Detach (if no other tickets exist) │
└─────────────────────────────────────────────────────────────┘
The Longhorn VolumeAttachment YAML during snapshot creation:
During Snapshot Creation (ticket exists):
apiVersion: longhorn.io/v1beta2
kind: VolumeAttachment
metadata:
name: pvc-0b9c8d59-0ae8-413c-8bc5-af32b932b8ab
namespace: longhorn-system
generation: 30
spec:
volume: pvc-0b9c8d59-0ae8-413c-8bc5-af32b932b8ab
attachmentTickets:
# Temporary ticket created by Snapshot Controller
snapshot-controller-snapshot-a36bedf5-fb3b-4b30-a10d-ed98f9c0323a:
id: snapshot-controller-snapshot-a36bedf5-fb3b-4b30-a10d-ed98f9c0323a
type: snapshot-controller
nodeID: harvester-node-1
parameters:
disableFrontend: any
status:
attachmentTicketStatuses:
snapshot-controller-snapshot-a36bedf5-fb3b-4b30-a10d-ed98f9c0323a:
id: snapshot-controller-snapshot-a36bedf5-fb3b-4b30-a10d-ed98f9c0323a
satisfied: false # Snapshot in progress
conditions:
- type: Satisfied
status: "False"
After Snapshot Completes (ticket removed):
apiVersion: longhorn.io/v1beta2
kind: VolumeAttachment
metadata:
name: pvc-0b9c8d59-0ae8-413c-8bc5-af32b932b8ab
namespace: longhorn-system
generation: 31 # Incremented after ticket removal
spec:
volume: pvc-0b9c8d59-0ae8-413c-8bc5-af32b932b8ab
attachmentTickets: {} # Ticket removed after snapshot completes
status:
attachmentTicketStatuses: {}
Key Observations:
- The
snapshot-controllerticket type clearly identifies this as a Longhorn internal operation - Unlike
csi-attachertickets (triggered by K8s), this ticket is created purely by Longhorn - The ticket is temporary - it appears during snapshot creation and disappears when complete
- No corresponding Kubernetes VolumeAttachment exists for this operation
Example 2: VM Migration
During VM migration, Harvester has two virt-launcher pods for the same VM: the original pod on the source node and a new pod on the target node. This multi-attach capability is enabled for RWX (ReadWriteMany) block mode volumes when the StorageClass has migratable: true parameter, which allows Longhorn to support live VM migration. In the following example, we migrate a VM from harvester-node-2 to harvester-node-0.
apiVersion: longhorn.io/v1beta2
kind: VolumeAttachment
metadata:
creationTimestamp: "2025-12-10T04:19:42Z"
finalizers:
- longhorn.io
generation: 3
labels:
longhornvolume: pvc-0dc9e1f0-4932-4567-aa1e-e70b570058da
name: pvc-0dc9e1f0-4932-4567-aa1e-e70b570058da
namespace: longhorn-system
ownerReferences:
- apiVersion: longhorn.io/v1beta2
kind: Volume
name: pvc-0dc9e1f0-4932-4567-aa1e-e70b570058da
uid: 7cd2ed46-194f-4528-83f7-bbaa5945e7e3
resourceVersion: "2736440"
uid: b2492681-8fcb-4330-9ec6-496afa93e96b
spec:
attachmentTickets:
csi-5852f2d48d96311bb582eeeaad0e38361031d502899416c71cea10795748a84b:
generation: 0
id: csi-5852f2d48d96311bb582eeeaad0e38361031d502899416c71cea10795748a84b
nodeID: harvester-node-2
parameters:
disableFrontend: "false"
lastAttachedBy: ""
type: csi-attacher
csi-f080d69495b619fad93621ff3d57201793952e422304cceac8807e975ccf795d:
generation: 0
id: csi-f080d69495b619fad93621ff3d57201793952e422304cceac8807e975ccf795d
nodeID: harvester-node-0
parameters:
disableFrontend: "false"
lastAttachedBy: ""
type: csi-attacher
volume: pvc-0dc9e1f0-4932-4567-aa1e-e70b570058da
status:
attachmentTicketStatuses:
csi-5852f2d48d96311bb582eeeaad0e38361031d502899416c71cea10795748a84b:
conditions:
- lastProbeTime: ""
lastTransitionTime: "2025-12-10T04:19:49Z"
message: ""
reason: ""
status: "True"
type: Satisfied
generation: 0
id: csi-5852f2d48d96311bb582eeeaad0e38361031d502899416c71cea10795748a84b
satisfied: true
csi-f080d69495b619fad93621ff3d57201793952e422304cceac8807e975ccf795d:
conditions:
- lastProbeTime: ""
lastTransitionTime: "2025-12-10T04:21:00Z"
message: The migrating attachment ticket is satisfied
reason: ""
status: "True"
type: Satisfied
generation: 0
id: csi-f080d69495b619fad93621ff3d57201793952e422304cceac8807e975ccf795d
satisfied: true
After Migration Completes (ticket removed):
apiVersion: longhorn.io/v1beta2
kind: VolumeAttachment
metadata:
creationTimestamp: "2025-12-10T04:19:42Z"
finalizers:
- longhorn.io
generation: 4
labels:
longhornvolume: pvc-0dc9e1f0-4932-4567-aa1e-e70b570058da
name: pvc-0dc9e1f0-4932-4567-aa1e-e70b570058da
namespace: longhorn-system
ownerReferences:
- apiVersion: longhorn.io/v1beta2
kind: Volume
name: pvc-0dc9e1f0-4932-4567-aa1e-e70b570058da
uid: 7cd2ed46-194f-4528-83f7-bbaa5945e7e3
resourceVersion: "2736824"
uid: b2492681-8fcb-4330-9ec6-496afa93e96b
spec:
attachmentTickets:
csi-f080d69495b619fad93621ff3d57201793952e422304cceac8807e975ccf795d:
generation: 0
id: csi-f080d69495b619fad93621ff3d57201793952e422304cceac8807e975ccf795d
nodeID: harvester-node-0
parameters:
disableFrontend: "false"
lastAttachedBy: ""
type: csi-attacher
volume: pvc-0dc9e1f0-4932-4567-aa1e-e70b570058da
status:
attachmentTicketStatuses:
csi-f080d69495b619fad93621ff3d57201793952e422304cceac8807e975ccf795d:
conditions:
- lastProbeTime: ""
lastTransitionTime: "2025-12-10T04:21:00Z"
message: ""
reason: ""
status: "True"
type: Satisfied
generation: 0
id: csi-f080d69495b619fad93621ff3d57201793952e422304cceac8807e975ccf795d
satisfied: true
Key Observations:
- Two CSI attachment tickets coexist: One pointing to the source node (harvester-node-2) and another to the target node (harvester-node-0)
- Both tickets are
csi-attachertype: Indicating they were both triggered by Kubernetes VolumeAttachment through the CSI flow - Both tickets have
satisfied: truestatus: This demonstrates Longhorn's support for attaching the same volume to multiple nodes simultaneously (RWX-like behavior for migration) - Target node ticket has special message: "The migrating attachment ticket is satisfied" explicitly identifies this as a migration scenario
- Multi-attach is temporary: This dual-attachment state only exists during VM migration; the source node's ticket will be removed after migration completes
Summary
Longhorn uses two different VolumeAttachment resources for different purposes:
Kubernetes VolumeAttachment (storage.k8s.io/v1) follows the standard CSI specification and is created only when Pods are scheduled to nodes. It represents Kubernetes' official attachment intent and is managed by K8s Attach/Detach Controller and CSI External-Attacher.
Longhorn VolumeAttachment (longhorn.io/v1beta2) extends beyond CSI to support Longhorn's advanced features. It's created for multiple scenarios, including Pod workloads, snapshots, backups, clones, and manual operations. It uses a ticket-based system to coordinate concurrent attachment requests and is managed collaboratively by multiple Longhorn controllers.
Why both are needed: K8s VolumeAttachment ensures CSI compliance with the Kubernetes ecosystem, while Longhorn VolumeAttachment enables automation for background operations without manual intervention. Importantly, not all Longhorn operations trigger K8s VolumeAttachment—for example, creating a VolumeSnapshot only creates a Longhorn VolumeAttachment ticket (snapshot-controller), not a K8s VolumeAttachment.
When troubleshooting: Check both resources. K8s VolumeAttachment shows the CSI standard workflow status, while Longhorn VolumeAttachment shows the complete picture, including all internal operations via attachment tickets. Look at the ticket type to identify the operation source: csi-attacher means triggered by the K8s VolumeAttachment (Pod workload), while snapshot-controller, backup-controller, etc. indicate Longhorn internal operations.