The Longhorn documentation provides best practice recommendations for deploying Longhorn in production environments. Before configuring workloads, ensure that you have set up the following basic requirements for optimal disk performance.
SATA/NVMe SSDs or disk drives with similar performance
10 Gbps network bandwidth between nodes
Dedicated Priority Classes for system-managed and user-deployed Longhorn components
The following sections outline other recommendations for achieving optimal disk performance.
Longhorn disk: Use a dedicated disk for Longhorn storage instead of using the root disk.
Replica count: Set the default replica count to "2" to achieve data availability with better disk space usage or less impact to system performance. This practice is especially beneficial to data-intensive applications.
Storage tag: Use storage tags to define storage tiering for data-intensive applications. For example, only high-performance disks can be used for storing performance-sensitive data. You can either add disks with tags or create StorageClasses with tags.
Data locality: Use best-effort as the default data locality of Longhorn Storage Classes.
For applications that support data replication (for example, a distributed database), you can use the strict-local option to ensure that only one replica is created for each volume. This practice prevents the extra disk space usage and IO performance overhead associated with volume replication.
For data-intensive applications, you can use pod scheduling functions such as node selector or taint toleration. These functions allow you to schedule the workload to a specific storage-tagged node together with one replica.
Recurring snapshots: Periodically clean up system-generated snapshots and retain only the number of snapshots that makes sense for your implementation.
Find the virtual machine that you want to migrate and select ⋮ > Migrate.
Choose the node to which you want to migrate the virtual machine and select Apply.
After successfully selecting Apply, a CRD VirtualMachineInstanceMigration object is created, and the related controller/operator will start the process.
When starting a virtual machine instance (VMI), it has also been calculated whether the machine is live migratable. The result is being stored in the VMI VMI.status.conditions. The calculation can be based on multiple parameters of the VMI, however, at the moment, the calculation is largely based on the Access Mode of the VMI volumes. Live migration is only permitted when the volume access mode is set to ReadWriteMany. Requests to migrate a non-LiveMigratable VMI will be rejected.
The reported Migration Method is also being calculated during VMI start. BlockMigration indicates that some of the VMI disks require copying from the source to the destination. LiveMigration means that only the instance memory will be copied.
VM Live Migration is a process during which a running Virtual Machine Instance moves to another compute node while the guest workload continues to run and remain accessible.
Understanding Different VM Live Migration Strategies
VM Live Migration is a complex process. During a migration, the source VM needs to transfer its whole state (mainly RAM) to the target VM. If there are enough resources available, such as network bandwidth and CPU power, migrations should converge nicely. If this is not the scenario, however, the migration might get stuck without an ability to progress.
The main factor that affects migrations from the guest perspective is its dirty rate, which is the rate by which the VM dirties memory. Guests with high dirty rate lead to a race during migration. On the one hand, memory would be transferred continuously to the target, and on the other, the same memory would get dirty by the guest. On such scenarios, one could consider to use more advanced migration strategies. Refer to Understanding different migration strategies for more details.
There are 3 VM Live Migration strategies/policies:
Pre-copy is the default strategy. It should be used for most cases.
The way it works is as following:
The target VM is created, but the guest keeps running on the source VM.
The source starts sending chunks of VM state (mostly memory) to the target. This continues until all of the state has been transferred to the target.
The guest starts executing on the target VM. 4. The source VM is being removed.
Pre-copy is the safest and fastest strategy for most cases. Furthermore, it can be easily cancelled, can utilize multithreading, and more. If there is no real reason to use another strategy, this is definitely the strategy to go with.
However, on some cases migrations might not converge easily, that is, by the time the chunk of source VM state would be received by the target VM, it would already be mutated by the source VM (which is the VM the guest executes on). There are many reasons for migrations to fail converging, such as a high dirty-rate or low resources like network bandwidth and CPU. On such scenarios, see the following alternative strategies below.
The way post-copy migrations work is as following:
The target VM is created.
The guest is being run on the target VM.
The source starts sending chunks of VM state (mostly memory) to the target.
When the guest, running on the target VM, would access memory: 1. If the memory exists on the target VM, the guest can access it. 2. Otherwise, the target VM asks for a chunk of memory from the source VM.
Once all of the memory state is updated at the target VM, the source VM is being removed.
The main idea here is that the guest starts to run immediately on the target VM. This approach has advantages and disadvantages:
Advantages:
The same memory chink is never being transferred twice. This is possible due to the fact that with post-copy it doesn't matter that a page had been dirtied since the guest is already running on the target VM.
This means that a high dirty-rate has much less effect.
Consumes less network bandwidth.
Disadvantages:
When using post-copy, the VM state has no one source of truth. When the guest (running on the target VM) writes to memory, this memory is one part of the guest's state, but some other parts of it may still be updated only at the source VM. This situation is generally dangerous, since, for example, if either the target or guest VMs crash the state cannot be recovered.
Slow warmup: when the guest starts executing, no memory is present at the target VM. Therefore, the guest would have to wait for a lot of memory in a short period of time.
Auto-converge is a technique to help pre-copy migrations converge faster without changing the core algorithm of how the migration works.
Since a high dirty-rate is usually the most significant factor for migrations to not converge, auto-converge simply throttles the guest's CPU. If the migration would converge fast enough, the guest's CPU would not be throttled or throttled negligibly. But, if the migration would not converge fast enough, the CPU would be throttled more and more as time goes.
This technique dramatically increases the probability of the migration converging eventually.
Observe the VM Live Migration Progress and Result
Depending on the type, the live migration process will copy virtual machine memory pages and disk blocks to the destination. During this process non-locked pages and blocks are being copied and become free for the instance to use again. To achieve a successful migration, it is assumed that the instance will write to the free pages and blocks (pollute the pages) at a lower rate than these are being copied.
In some cases the virtual machine can write to different memory pages / disk blocks at a higher rate than these can be copied, which will prevent the migration process from completing in a reasonable amount of time. In this case, live migration will be aborted if it is running for a long period of time. The timeout is calculated base on the size of the VMI, it's memory and the ephemeral disks that are needed to be copied. The configurable parameter completionTimeoutPerGiB, which defaults to 800s is the time for GiB of data to wait for the migration to be completed before aborting it. A VMI with 8Gib of memory will time out after 6400 seconds.
A VM Live Migration will also be aborted when it notices that copying memory doesn't make any progress. The time to wait for live migration to make progress in transferring data is configurable by the progressTimeout parameter, which defaults to 150 seconds.
KubeVirt puts some limits in place so that migrations don't overwhelm the cluster. By default, it is to only run 5 migrations in parallel with an additional limit of a maximum of 2 outbound migrations per node. Finally, every migration is limited to a bandwidth of 64MiB/s.
You can change these values in the kubevirt CR:
apiVersion: kubevirt.io/v1 kind: Kubevirt metadata: name: kubevirt namespace: kubevirt spec: configuration: migrations: parallelMigrationsPerCluster: 5 parallelOutboundMigrationsPerNode: 2 bandwidthPerMigration: 64Mi completionTimeoutPerGiB: 800 progressTimeout: 150 disableTLS: false nodeDrainTaintKey: "kubevirt.io/drain" allowAutoConverge: false ---------------------> related to: Auto-converge allowPostCopy: false -------------------------> related to: Post-copy unsafeMigrationOverride: false
Remember that most of these configurations can be overridden and fine-tuned to a specified group of VMs. For more information, please refer to the Migration Policies section below.
Migration policies provides a new way of applying migration configurations to Virtual Machines. The policies can refine Kubevirt CR's MigrationConfiguration that sets the cluster-wide migration configurations. This way, the cluster-wide settings default how the migration policy can be refined (i.e., changed, removed, or added).
Remember that migration policies are in version v1alpha1. This means that this API is not fully stable yet and that APIs may change in the future.
Currently, the MigrationPolicy spec only includes the following configurations from Kubevirt CR's MigrationConfiguration. (In the future, more configurations that aren't part of Kubevirt CR will be added):
All the above fields are optional. When omitted, the configuration will be applied as defined in KubevirtCR's MigrationConfiguration. This way, KubevirtCR will serve as a configurable set of defaults for both VMs that are not bound to any MigrationPolicy and VMs that are bound to a MigrationPolicy that does not define all fields of the configurations.
Next in the spec are the selectors defining the group of VMs to apply the policy. The options to do so are the following.
This policy applies to the VMs in namespaces that have all the required labels:
apiVersion: migrations.kubevirt.io/v1alpha1 kind: MigrationPolicy spec: selectors: namespaceSelector: hpc-workloads: true # Matches a key and a value
The policy below applies to the VMs that have all the required labels:
apiVersion: migrations.kubevirt.io/v1alpha1 kind: MigrationPolicy spec: selectors: virtualMachineInstanceSelector: workload-type: db # Matches a key and a value
/* Enable algorithms that ensure a live migration will eventually converge. * This usually means the domain will be slowed down to make sure it does * not change its memory faster than a hypervisor can transfer the changed * memory to the destination host. VIR_MIGRATE_PARAM_AUTO_CONVERGE_* * parameters can be used to tune the algorithm. * * Since: 1.2.3 */ VIR_MIGRATE_AUTO_CONVERGE = (1 << 13), ... /* Setting the VIR_MIGRATE_POSTCOPY flag tells libvirt to enable post-copy * migration. However, the migration will start normally and * virDomainMigrateStartPostCopy needs to be called to switch it into the * post-copy mode. See virDomainMigrateStartPostCopy for more details. * * Since: 1.3.3 */ VIR_MIGRATE_POSTCOPY = (1 << 15),
Starting with Harvester v1.2.0, it offers the capability to install a Container Storage Interface (CSI) in your Harvester cluster. This allows you to leverage external storage for the Virtual Machine's non-system data disk, giving you the flexibility to use different drivers tailored for specific needs, whether it's for performance optimization or seamless integration with your existing in-house storage solutions.
It's important to note that, despite this enhancement, the provisioner for the Virtual Machine (VM) image in Harvester still relies on Longhorn. Prior to version 1.2.0, Harvester exclusively supported Longhorn for storing VM data and did not offer support for external storage as a destination for VM data.
One of the options for integrating external storage with Harvester is Rook, an open-source cloud-native storage orchestrator. Rook provides a robust platform, framework, and support for Ceph storage, enabling seamless integration with cloud-native environments.
Ceph is a software-defined distributed storage system that offers versatile storage capabilities, including file, block, and object storage. It is designed for large-scale production clusters and can be deployed effectively in such environments.
Rook simplifies the deployment and management of Ceph, offering self-managing, self-scaling, and self-healing storage services. It leverages Kubernetes resources to automate the deployment, configuration, provisioning, scaling, upgrading, and monitoring of Ceph.
In this article, we will walk you through the process of installing, configuring, and utilizing Rook to use storage from an existing external Ceph cluster as a data disk for a VM within the Harvester environment.
Harvester's operating system follows an immutable design, meaning that most OS files revert to their pre-configured state after a reboot. To accommodate Rook Ceph's requirements, you need to add specific persistent paths to the os.persistentStatePaths section in the Harvester configuration. These paths include:
Consume the external Ceph cluster resources on the Harvester cluster.
# Paste the above output from create-external-cluster-resources.py into import-env.sh vim import-env.sh source import-env.sh # this script will create a StorageClass ceph-rbd source import-external-cluster.sh
kubectl apply -f common-external.yaml kubectl apply -f cluster-external.yaml # wait for all pods to become Ready watch'kubectl --namespace rook-ceph get pods'
Create the VolumeSnapshotClass csi-rbdplugin-snapclass-external.
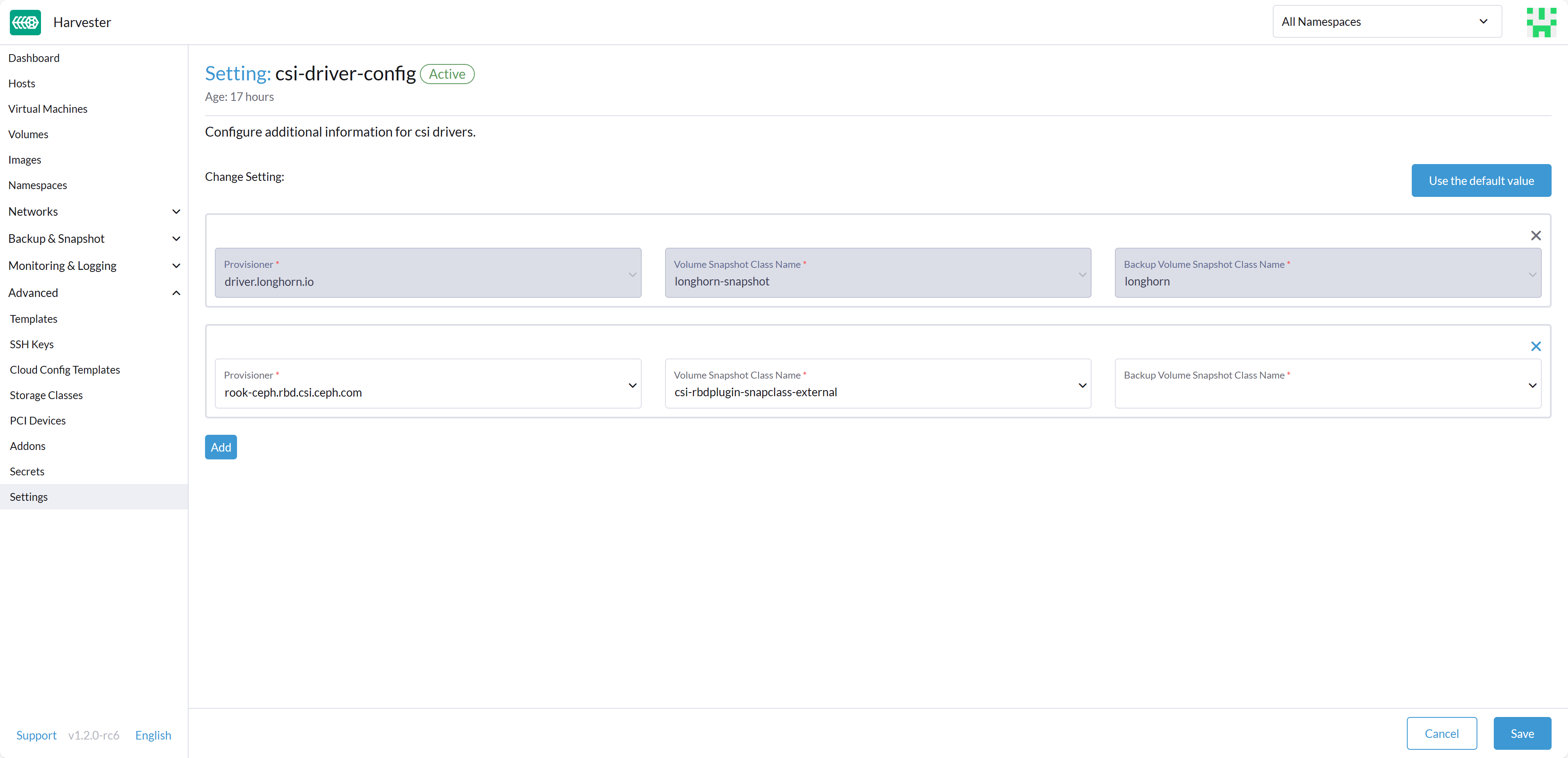
Before you can make use of Harvester's Backup & Snapshot features, you need to set up some essential configurations through the Harvester csi-driver-config setting. To set up these configurations, follow these steps:
Login to the Harvester UI, then navigate to Advanced > Settings.
Find and select csi-driver-config, and then click on the ⋮ > Edit Setting to access the configuration options.
In the settings, set the Provisioner to rook-ceph.rbd.csi.ceph.com.
Next, specify the Volume Snapshot Class Name as csi-rbdplugin-snapclass-external. This setting points to the name of the VolumeSnapshotClass used for creating volume snapshots or VM snapshots.
After successfully configuring these settings, you can proceed to utilize the Rook Ceph StorageClass, which is named rook-ceph-block for the internal Ceph cluster or named ceph-rbd for the external Ceph cluster. You can apply this StorageClass when creating an empty volume or adding a new block volume to a VM, enhancing your Harvester cluster's storage capabilities.
With these configurations in place, your Harvester cluster is ready to make the most of the Rook Ceph storage integration.
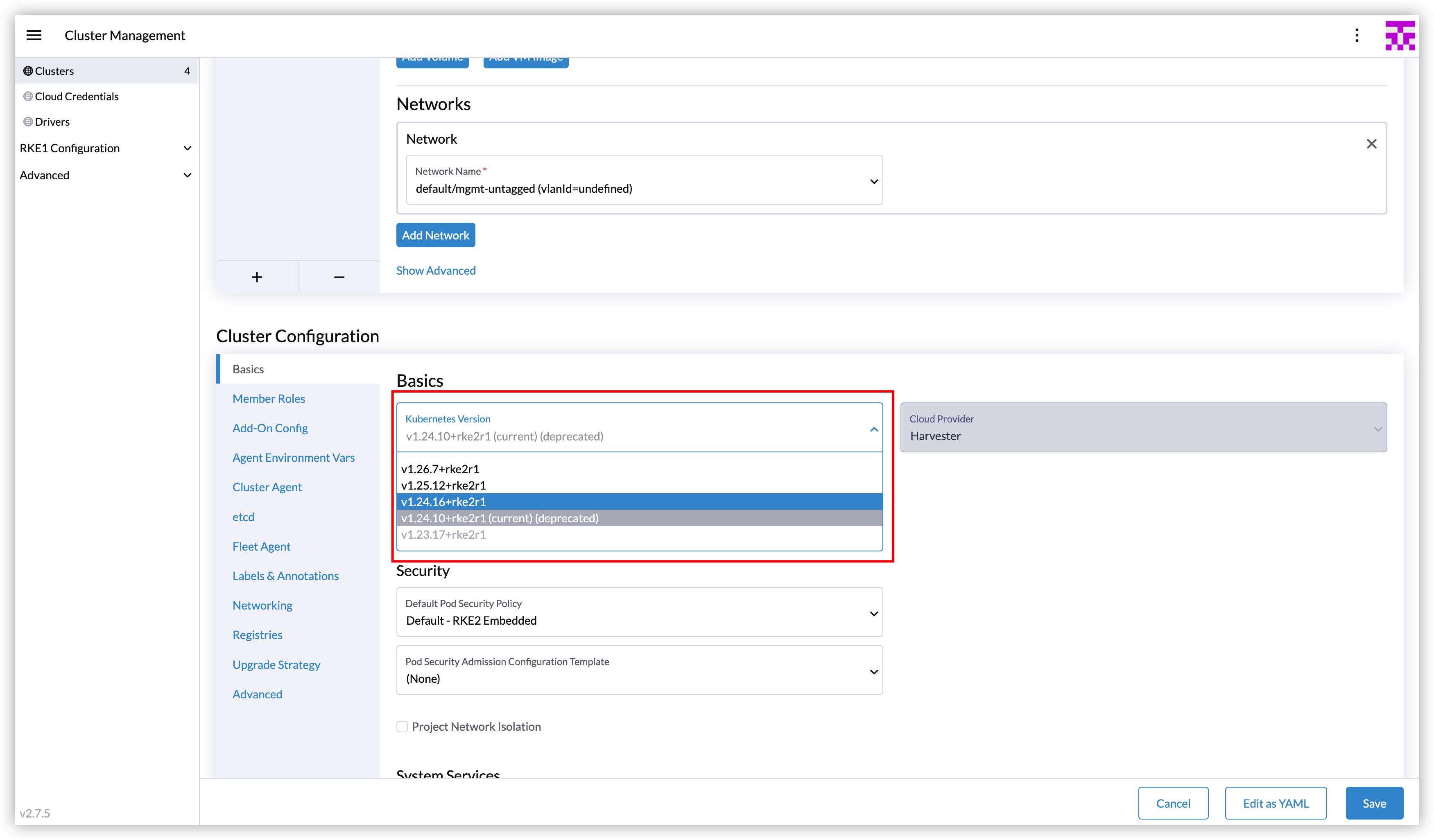
As Harvester v1.2.0 is released, a new Harvester cloud provider version 0.2.2 is integrated into RKE2 v1.24.15+rke2r1, v1.25.11+rke2r1, v1.26.6+rke2r1, v1.27.3+rke2r1, and newer versions.
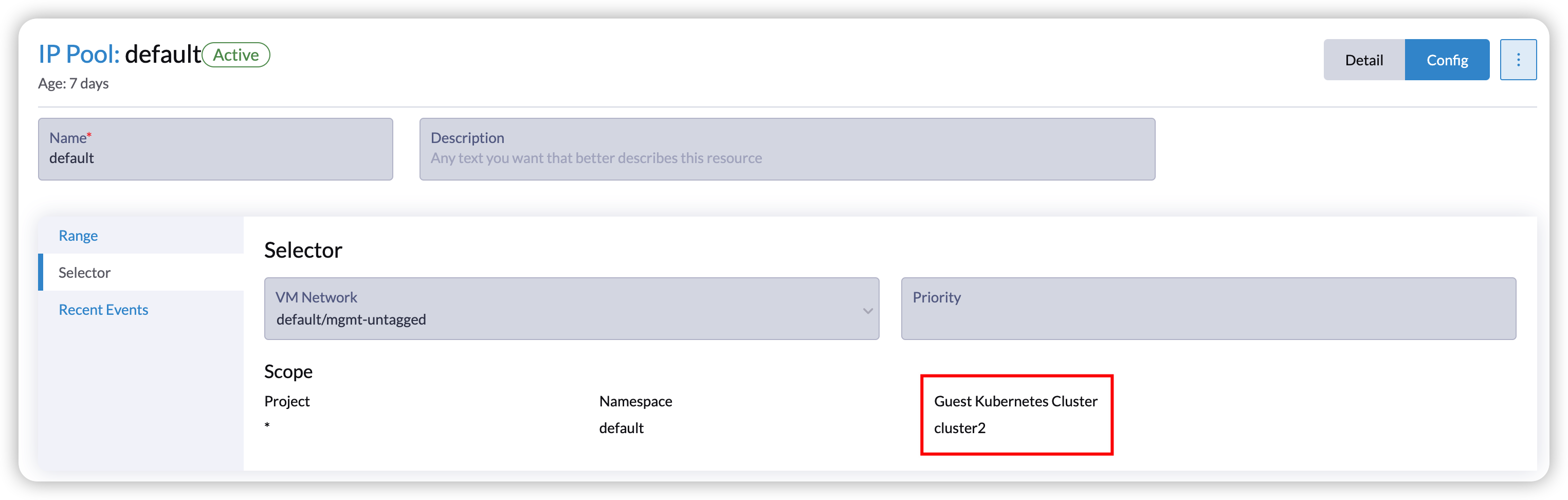
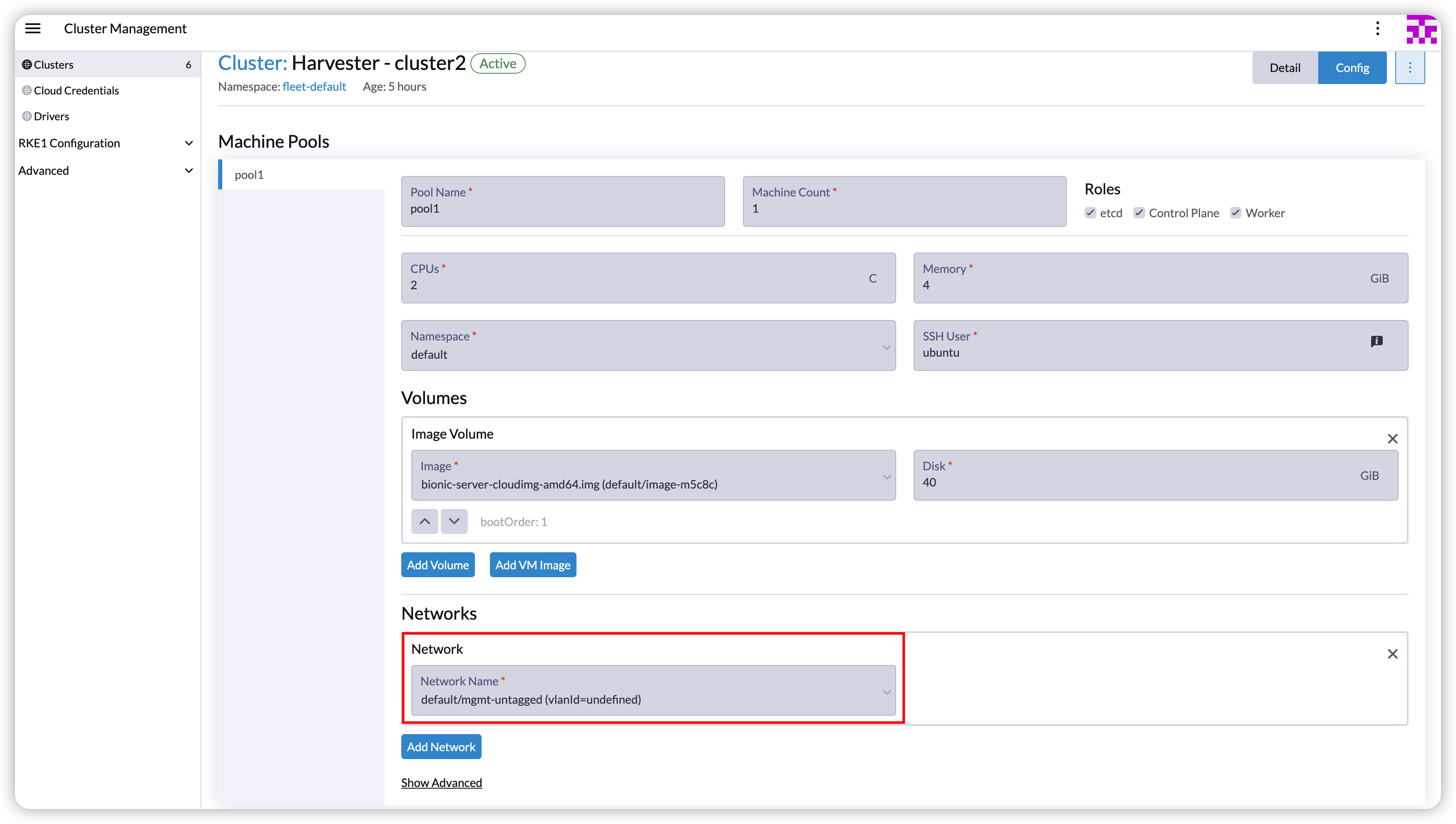
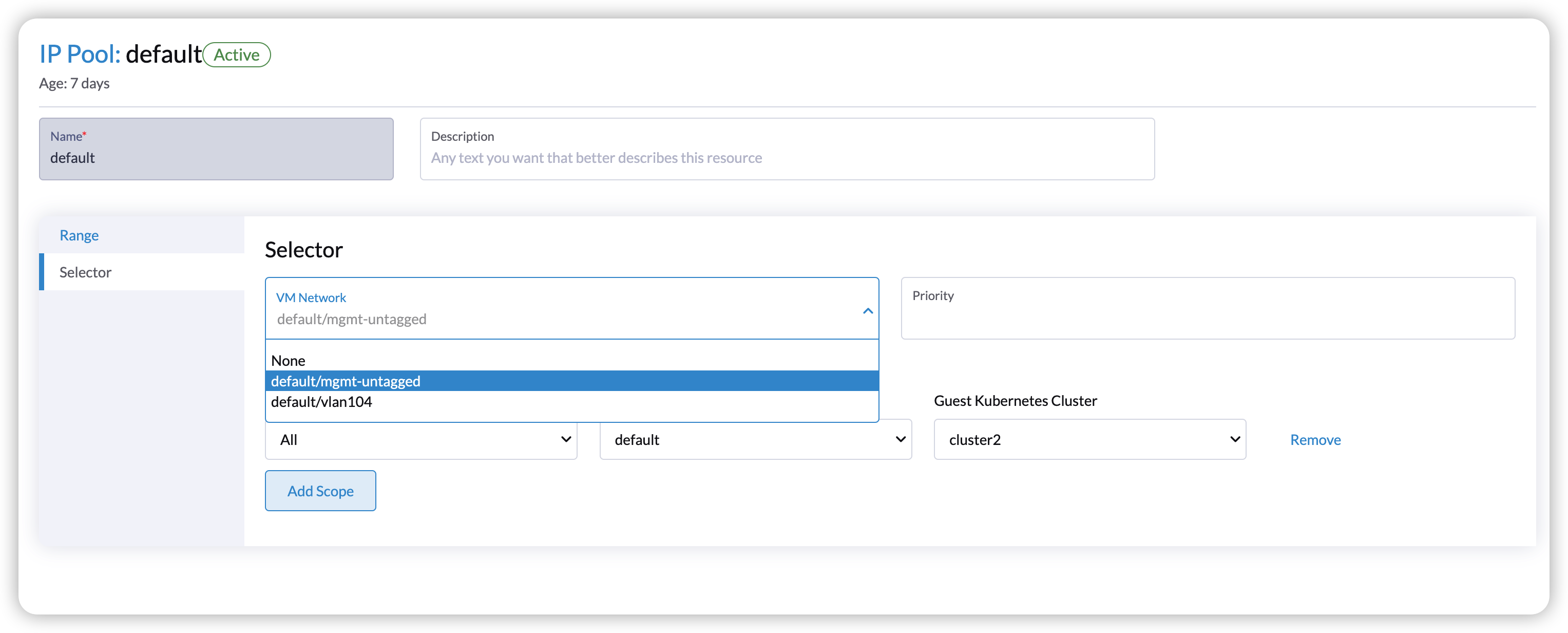
With Harvester v1.2.0, the new Harvester cloud provider offers enhanced load balancing capabilities for guest Kubernetes services. Specifically, it introduces the Harvester IP Pool feature, a built-in IP address management (IPAM) solution for the Harvester load balancer. It allows you to define an IP pool specific to a particular guest cluster by specifying the guest cluster name. For example, you can create an IP pool exclusively for the guest cluster named cluster2:
However, after upgrading, the feature is not automatically compatible with existing guest Kubernetes clusters, as they do not pass the correct cluster name to the Harvester cloud provider. Refer to issue 4232 for more details. Users can manually upgrade the Harvester cloud provider using Helm as a workaround and provide the correct cluster name after upgrading. However, this would result in a change in the load balancer IPs.
This article outlines a workaround that allows you to leverage the new IP pool feature while keeping the load balancer IPs unchanged.
Download the Harvester kubeconfig file from the Harvester UI. If you have imported Harvester into Rancher, do not use the kubeconfig file from the Rancher UI. Refer to Access Harvester Cluster to get the desired one.
<Harvester-kubeconfig-path>: Path to the Harvester kubeconfig file.
<guest-cluster-kubeconfig-path>: Path to the kubeconfig file of your guest Kubernetes cluster.
<guest-cluster-name>: Name of your guest cluster.
<guest-cluster-nodes-namespace>: Namespace where the VMs of the guest cluster are located.
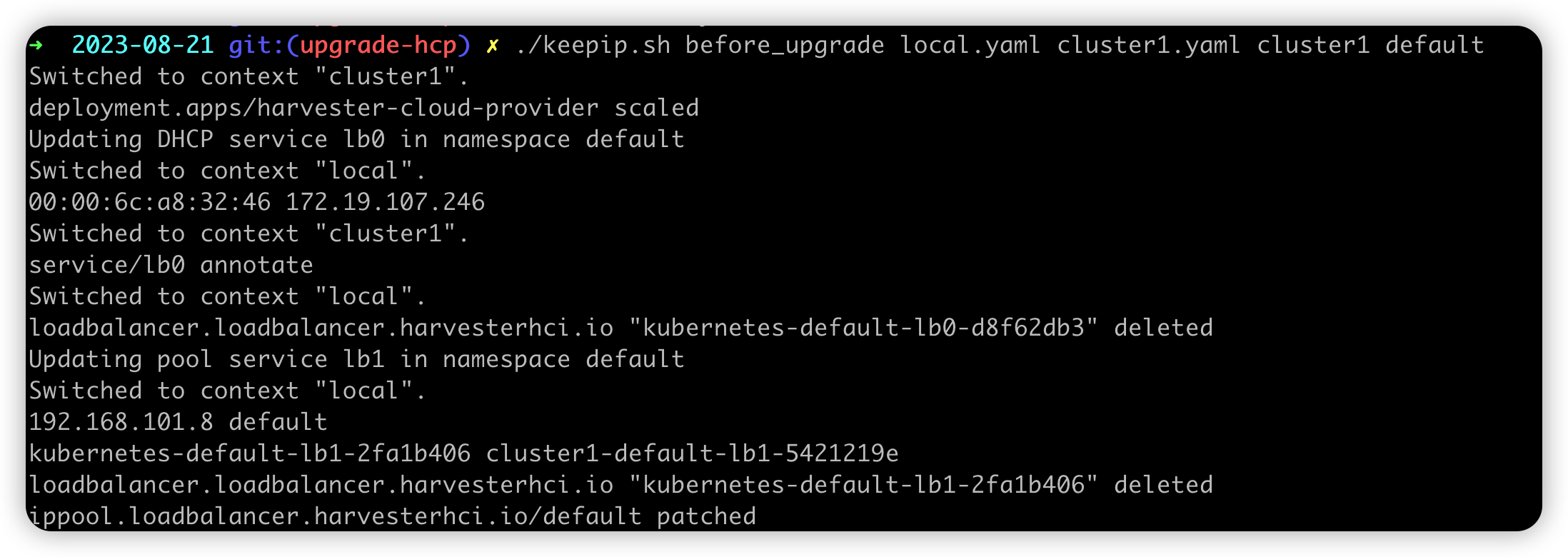
The script will help users copy the DHCP information to the service annotation and modify the IP pool allocated history to make sure the IP is unchanged.
After executing the script, the load balancer service with DHCP mode will be annotated with the DHCP information. For example:
In this step, the script wraps the operations to upgrade the Harvester cloud provider to set the cluster name. After the Harvester cloud provider is running, the new Harvester load balancers will be created with the unchanged IPs.
This article covers instructions for installing the Netapp Astra Trident CSI driver into a Harvester cluster, which enables NetApp storage systems to store storage volumes usable by virtual machines running in Harvester.
The NetApp storage will be an option in addition to the normal Longhorn storage; it will not replace Longhorn. Virtual machine images will still be stored using Longhorn.
This has been tested with Harvester 1.2.0 and Trident v23.07.0.
This procedure only works to access storage via iSCSI, not NFS.
note
3rd party storage classes (including those based on Trident) can only be used for non-boot volumes of Harvester VMs.
Detailed Instructions
We assume that before beginning this procedure, a Harvester cluster and a NetApp ONTAP storage system are both installed and configured for use.
Most of these steps can be performed on any system with the helm and kubectl commands installed and network connectivity to the management port of the Harvester cluster. Let's call this your workstation. Certain steps must be performed on one or more cluster nodes themselves. The steps described below should be done on your workstation unless otherwise indicated.
The last step (enabling multipathd) should be done on all nodes after the Trident CSI has been installed.
Certain parameters of your installation will require modification of details in the examples in the procedure given below. Those which you may wish to modify include:
The namespace. trident is used as the namespace in the examples, but you may prefer to use another.
The name of the deployment. mytrident is used but you can change this to something else.
The management IP address of the ONTAP storage system
Login credentials (username and password) of the ONTAP storage system
The simplest method is to install using Helm; that process is described here.
Download the KubeConfig from the Harvester cluster.
Open the web UI for your Harvester cluster
In the lower left corner, click the "Support" link. This will take you to a "Harvester Support" page.
Click the button labeled "Download KubeConfig". This will download a your cluster config in a file called "local.yaml" by default.
Move this file to a convenient location and set your KUBECONFIG environment variable to the path of this file.
Prepare the cluster for installation of the Helm chart.
Before starting installation of the helm chart, special authorization must be provided to enable certain modifications to be made during the installation.
This addresses the issue described here: https://github.com/NetApp/trident/issues/839
Put the following text into a file. For this example we'll call it authorize_trident.yaml.
Set these variables for the Helm chart you are installing:
helm search repo netapp-trident --versions
exportCHART_VERSION="" exportAPP_VERSION=""
Next, install the Helm chart. This example uses trident as the deployment name, trident as the namespace, and 100.2406.1 as the Helm chart version to install:
The NetApp documentation describes variations on how you can do this.
Download and extract the tridentctl command, which will be needed for the next few steps.
This and the next few steps need to be performed logged into a master node of the Harvester cluster, using root access.
cd /tmp curl -L -o trident-installer-${APP_VERSION}.tar.gz https://github.com/NetApp/trident/releases/download/v${APP_VERSION}/trident-installer-${APP_VERSION}.tar.gz tar -xf trident-installer-${APP_VERSION}.tar.gz cd trident-installer
Install a backend.
This part is specific to Harvester.
Create the following text file:
cat <<EOF> /tmp/backend.yaml version:1 backendName: default_backend_san storageDriverName: <<ontap-san-economy or ontap-san>> managementLIF: <<ADMIN_IPADDRESS>>## Often the same as the storage UI IP address dataLIF: <<DATA_IPADDRESS>>## IP assigned to the iSCSI-only SVM svm: <<SVM_NAME>> username: <<ONTAP storage admin user>> password: <<password>> labels: name: default_backend_san EOF
Update the IP addresses, SVM name, username, and password in this file
with the appropriate values for the the ONTAP system.
Select the correct value for the backendType in this file before applying.
Apply the definitions:
kubectl apply -f /tmp/storage.yaml
Enable multipathd
The following is required to enable multipathd.
This must be done on every node of the Harvester cluster, using root access.
The preceding steps should only be done once on a single node.
Configure multipathd to exclude pathnames used by Longhorn.
This part is a little tricky. multipathd will automatically discover
device names matching a certain pattern, and attempt to set up multipathing on them.
Unfortunately, Longhorn's device names follow the same pattern, and
will not work correctly if multipathd tries to use those devices.
Therefore the file /etc/multipath.conf must be set up on each node
so as to prevent multipathd from touching any of the devices
that Longhorn will use. Unfortunately, it is not possible to know
in advance which device names will be used until the volumes are attached
to a VM when the VM is started, or when the volumes are hot-added to a running VM.
The recommended method is to "whitelist" the Trident devices using device
properties rather than device naming. The properties to allow are the
device vendor and product. Here is an example of what you'll want in /etc/multipath.conf:
This example only works if NetApp is the only storage provider in the system for which multipathd must be used. More complex environments will require more complex configuration.
Explicitly putting that content into /etc/multipath.conf will work when you start multipathd as described below, but the change in /etc will not persist across node reboots. To solve that problem, you should add another file to /oem that will re-generate /etc/multipath.conf when the node reboots. The following example will create the /etc/multipath.conf given in the example above, but may need to be modified for your environment if you have a more complex iSCSI configuration:
Adding the above files to /oem will take effect on the next reboot of the node; multipathd can be enabled immediately without rebooting the node using the following commands:
Harvester v1.2.0 introduces a new enhancement where Longhorn system-managed components in newly-deployed clusters are automatically assigned a system-cluster-critical priority class by default. However, when upgrading your Harvester clusters from previous versions, you may notice that Longhorn system-managed components do not have any priority class set.
This behavior is intentional and aimed at supporting zero-downtime upgrades. Longhorn does not allow changing the priority-class setting when attached volumes exist. For more details, please refer to Setting Priority Class During Longhorn Installation).
This article explains how to manually configure priority classes for Longhorn system-managed components after upgrading your Harvester cluster, ensuring that your Longhorn components have the appropriate priority class assigned and maintaining the stability and performance of your system.
Get all running VMs and write down their namespaces and names:
kubectl get vmi -A
Alternatively, you can get this information by backing up the Virtual Machine Instance (VMI) manifests with the following command:
kubectl get vmi -A -o json > vmi-backup.json
Shut down all VMs. Log in to all running VMs and shut them down gracefully (recommended). Or use the following command to send shutdown signals to all VMs:
kubectl get vmi -A -o json | jq -r '.items[] | [.metadata.name, .metadata.namespace] | @tsv'|whileIFS=$'\t'read -r name namespace;do if[ -z "$name"];then break fi echo"Stop ${namespace}/${name}" virtctl stop $name -n $namespace done
Check if the vm-import-controller addon is enabled and configured with a persistent volume with the following command:
kubectl get pvc -n harvester-system harvester-vm-import-controller
If the above command returns an output like this, you must scale down the vm-import-controller pod. Otherwise, you can skip the following step.
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE harvester-vm-import-controller Bound pvc-eb23e838-4c64-4650-bd8f-ba7075ab0559 200Gi RWO harvester-longhorn 2m53s
Scale down the vm-import-controller pods with the following command:
Before applying the priority-class setting, you need to verify all volumes are detached. Run the following command to verify the STATE of each volume is detached:
deployment.apps/harvester-vm-import-controller scaled Waiting for deployment "harvester-vm-import-controller" rollout to finish: 0 of 1 updated replicas are available... deployment "harvester-vm-import-controller" successfully rolled out
Verify vm-import-controller is running using the following command:
kubectl get pods --selector app.kubernetes.io/instance=vm-import-controller -A
A sample output looks like this, the pod's STATUS must be Running:
NAMESPACE NAME READY STATUS RESTARTS AGE harvester-system harvester-vm-import-controller-6bd8f44f55-m9k86 1/1 Running 0 4m53s
prometheus.monitoring.coreos.com/rancher-monitoring-prometheus patched Waiting for 1 pods to be ready... statefulset rolling update complete 1 pods at revision prometheus-rancher-monitoring-prometheus-cbf6bd5f7...
Scale down the AlertManager deployment. Run the following command and wait for all AlertManager pods to roll out:
alertmanager.monitoring.coreos.com/rancher-monitoring-alertmanager patched Waiting for 1 pods to be ready... statefulset rolling update complete 1 pods at revision alertmanager-rancher-monitoring-alertmanager-c8bd4466c...
Scale down the Grafana deployment. Run the following command and wait for all Grafana pods to roll out:
deployment.apps/rancher-monitoring-grafana scaled Waiting for deployment "rancher-monitoring-grafana" rollout to finish: 0 of 1 updated replicas are available... deployment "rancher-monitoring-grafana" successfully rolled out
Harvester OS is designed as an immutable operating system, which means you cannot directly install additional packages on it. While there is a way to install packages, it is strongly advised against doing so, as it may lead to system instability.
If you only want to debug with the system, the preferred way is to package the toolbox image with all the needed packages.
This article shares how to package your toolbox image and how to install any packages on the toolbox image that help you debug the system.
For example, if you want to analyze a storage performance issue, you can install blktrace on the toolbox image.
# use `privileged` flag only when you needed. blktrace need debugfs, so I add extra mountpoint. docker run -it --privileged -v /sys/kernel/debug/:/sys/kernel/debug/ --rm harvester/toolbox:dev bash # test blktrace 6ffa8eda3aaf:/ $ blktrace -d /dev/nvme0n1 -o - | blkparse -i - 259,01034140.02081487534084 Q WS 2414127984 + 8[fio] 259,01034150.02081519034084 G WS 2414127984 + 8[fio] 259,01034160.02081598934084 C WS 3206896544 + 8[0] 259,01034170.02081665234084 C WS 2140319184 + 8[0] 259,01034180.02081799234084 P N [fio] 259,01034190.02081822734084 U N [fio]1 259,01034200.02081843734084 D WS 2414127984 + 8[fio] 259,01034210.02082182634084 Q WS 1743934904 + 8[fio] 259,01034220.02082215034084 G WS 1743934904 + 8[fio]