For Harvester to successfully migrate a virtual machine from one node to another, the source and target nodes must have compatible CPU models and features.
Harvester uses KubeVirt / QEMU / libvirt to manage and run virtual machines. When a VM starts, libvirt exposes a specific CPU feature set to the guest operating system. Live migration requires this CPU feature set to be identical on both source and target nodes.
Different CPU generations support different instruction sets and feature flags. If those differ, the live migration will be blocked to avoid instability or incorrect execution on the target node.
If the CPU model of a virtual machine isn't specified, KubeVirt assigns it the default host-model configuration so that the virtual machine has the CPU model closest to the one used on the host node.
KubeVirt automatically adjusts the node selectors of the associated virt-launcher Pod based on this configuration. If the CPU models and features of the source and target nodes do not match, the live migration may fail.
Let's examine an example.
When a virtual machine is first migrated to another node with the SierraForest CPU model, the following key-value pairs are added to the spec.nodeSelector field in the Pod spec.
The above nodeSelector configuration is retained for subsequent migrations, which may fail if the new target node doesn't have the corresponding features or model.
For example, compare the CPU model and feature labels added by KubeVirt to the following two nodes:
# Node A labels: cpu-model-migration.node.kubevirt.io/SierraForest:"true" cpu-feature.node.kubevirt.io/fpu:"true" cpu-feature.node.kubevirt.io/vme:"true" # Node B labels: cpu-model-migration.node.kubevirt.io/SierraForest:"true" cpu-feature.node.kubevirt.io/vme:"true"
This virtual machine will fail to migrate to Node B due to the missing fpu feature. However, if the virtual machine doesn't actually require this feature, this can be frustrating. Therefore, setting up a common CPU model can resolve this issue.
You can define a custom CPU model to ensure that the spec.nodeSelector configuration in the Pod spec is assigned a CPU model that is compatible and common to all nodes in the cluster.
Consider this example.
We have the following node information:
# Node A labels: cpu-model.node.kubevirt.io/IvyBridge:"true" cpu-feature.node.kubevirt.io/fpu:"true" cpu-feature.node.kubevirt.io/vme:"true" # Node B labels: cpu-model.node.kubevirt.io/IvyBridge:"true" cpu-feature.node.kubevirt.io/vme:"true"
If we set up IvyBridge as our CPU model in the virtual machine spec, KubeVirt only adds cpu-model.node.kubevirt.io/IvyBridge under spec.nodeSelector in the Pod spec.
Harvester allows the CPU model to be defined in the VM specification.
If host-passthrough is used, the VM exposes the exact host CPU to the guest. This provides maximum performance but completely prevents migration across different CPU generations.
If host-model is used, the VM derives a CPU model based on the host’s capabilities. This works only when all nodes expose identical CPU features. In mixed clusters, this setting commonly causes migration failures.
If an explicit CPU model is defined, the VM exposes a named CPU architecture defined by QEMU. This is the recommended approach for clusters that may contain different CPU generations.
For mixed environments, an explicit CPU model should always be used.
When selecting a CPU model, the goal is to choose the highest common denominator. This means the most modern CPU architecture that every node in the cluster supports. Pick a model supported by all nodes in your cluster, including the oldest CPU generation. Use a server-grade model that provides a reasonable set of capabilities (e.g., vector instructions, security features) without tying VMs to host-specific features. Use the same model on all VMs that need live migration.
Below are practical examples for common enterprise hardware combinations.
For a cluster that mixes Cascade Lake and Sapphire Rapids, the recommended CPU model is Cascadelake-Server. Sapphire Rapids processors are backward compatible with Cascade Lake instructions, making Cascadelake-Server the highest common denominator between these two generations.
For a cluster that mixes Skylake and Cascade Lake nodes, the appropriate model is Skylake-Server. This is the common ground between both generations. Cascade Lake includes additional AVX-512 optimizations, but using Skylake ensures compatibility across the entire cluster.
If your cluster contains Broadwell nodes along with anything newer, the safest baseline is Broadwell. Broadwell serves as a stable and widely supported baseline for older enterprise hardware. Any newer CPUs will support it.
If your virtual machines run only on a specific CPU model, you can set up a cluster-wide CPU model in the kubevirt resource.
You can edit it with kubectl edit kubevirt kubevirt -n harvester-system, then add the CPU model you want in the following spec:
spec: configuration: cpuModel: IvyBridge
Then, when a new virtual machine starts or an existing virtual machine restarts, the cluster-wide setting will be applied. The system follows these priorities when using CPU models if you configure them in both locations:
We have the default SSH user rancher, but other users may be required. Creating users with useradd will result in their deletion upon restarting the Harvester node; therefore, follow the steps below to create persistent SSH users.
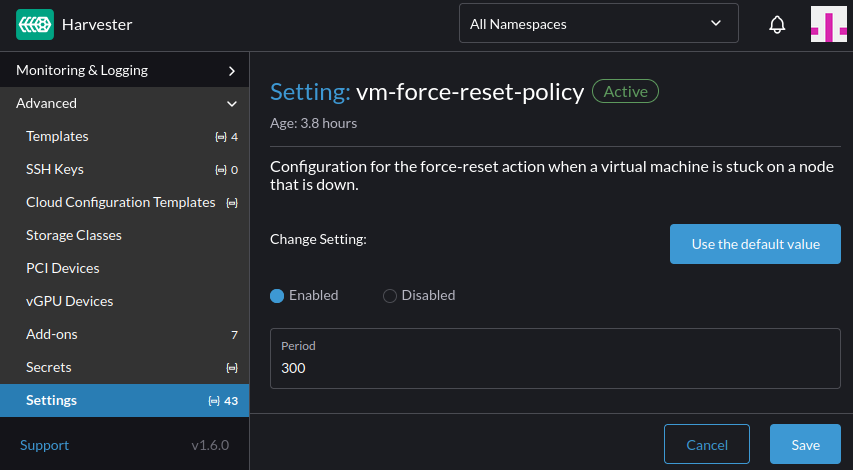
If a Harvester node becomes unreachable, Harvester attempts to reschedule its virtual machines to another healthy node. However, this rescheduling doesn't happen immediately. The associated virt-launcher pods may continue to appear to remain in the ready state due to its KubeVirt readiness gate configuration.
To mitigate this elapsed time, you can modify the vm-force-reset-policy setting, by reducing its period value. This enables Harvester to detect non-ready virtual machines on unreachable nodes sooner.
This setting can be found in the Advanced -> Settings page on the Harvester UI.
Additionally, while the current default is 5 minutes, we are considering reducing the default value [1].
Find the virtual machine that you want to migrate and select ⋮ > Migrate.
Choose the node to which you want to migrate the virtual machine and select Apply.
After successfully selecting Apply, a CRD VirtualMachineInstanceMigration object is created, and the related controller/operator will start the process.
When starting a virtual machine instance (VMI), it has also been calculated whether the machine is live migratable. The result is being stored in the VMI VMI.status.conditions. The calculation can be based on multiple parameters of the VMI, however, at the moment, the calculation is largely based on the Access Mode of the VMI volumes. Live migration is only permitted when the volume access mode is set to ReadWriteMany. Requests to migrate a non-LiveMigratable VMI will be rejected.
The reported Migration Method is also being calculated during VMI start. BlockMigration indicates that some of the VMI disks require copying from the source to the destination. LiveMigration means that only the instance memory will be copied.
VM Live Migration is a process during which a running Virtual Machine Instance moves to another compute node while the guest workload continues to run and remain accessible.
Understanding Different VM Live Migration Strategies
VM Live Migration is a complex process. During a migration, the source VM needs to transfer its whole state (mainly RAM) to the target VM. If there are enough resources available, such as network bandwidth and CPU power, migrations should converge nicely. If this is not the scenario, however, the migration might get stuck without an ability to progress.
The main factor that affects migrations from the guest perspective is its dirty rate, which is the rate by which the VM dirties memory. Guests with high dirty rate lead to a race during migration. On the one hand, memory would be transferred continuously to the target, and on the other, the same memory would get dirty by the guest. On such scenarios, one could consider to use more advanced migration strategies. Refer to Understanding different migration strategies for more details.
There are 3 VM Live Migration strategies/policies:
Pre-copy is the default strategy. It should be used for most cases.
The way it works is as following:
The target VM is created, but the guest keeps running on the source VM.
The source starts sending chunks of VM state (mostly memory) to the target. This continues until all of the state has been transferred to the target.
The guest starts executing on the target VM. 4. The source VM is being removed.
Pre-copy is the safest and fastest strategy for most cases. Furthermore, it can be easily cancelled, can utilize multithreading, and more. If there is no real reason to use another strategy, this is definitely the strategy to go with.
However, on some cases migrations might not converge easily, that is, by the time the chunk of source VM state would be received by the target VM, it would already be mutated by the source VM (which is the VM the guest executes on). There are many reasons for migrations to fail converging, such as a high dirty-rate or low resources like network bandwidth and CPU. On such scenarios, see the following alternative strategies below.
The way post-copy migrations work is as following:
The target VM is created.
The guest is being run on the target VM.
The source starts sending chunks of VM state (mostly memory) to the target.
When the guest, running on the target VM, would access memory: 1. If the memory exists on the target VM, the guest can access it. 2. Otherwise, the target VM asks for a chunk of memory from the source VM.
Once all of the memory state is updated at the target VM, the source VM is being removed.
The main idea here is that the guest starts to run immediately on the target VM. This approach has advantages and disadvantages:
Advantages:
The same memory chink is never being transferred twice. This is possible due to the fact that with post-copy it doesn't matter that a page had been dirtied since the guest is already running on the target VM.
This means that a high dirty-rate has much less effect.
Consumes less network bandwidth.
Disadvantages:
When using post-copy, the VM state has no one source of truth. When the guest (running on the target VM) writes to memory, this memory is one part of the guest's state, but some other parts of it may still be updated only at the source VM. This situation is generally dangerous, since, for example, if either the target or guest VMs crash the state cannot be recovered.
Slow warmup: when the guest starts executing, no memory is present at the target VM. Therefore, the guest would have to wait for a lot of memory in a short period of time.
Auto-converge is a technique to help pre-copy migrations converge faster without changing the core algorithm of how the migration works.
Since a high dirty-rate is usually the most significant factor for migrations to not converge, auto-converge simply throttles the guest's CPU. If the migration would converge fast enough, the guest's CPU would not be throttled or throttled negligibly. But, if the migration would not converge fast enough, the CPU would be throttled more and more as time goes.
This technique dramatically increases the probability of the migration converging eventually.
Observe the VM Live Migration Progress and Result
Depending on the type, the live migration process will copy virtual machine memory pages and disk blocks to the destination. During this process non-locked pages and blocks are being copied and become free for the instance to use again. To achieve a successful migration, it is assumed that the instance will write to the free pages and blocks (pollute the pages) at a lower rate than these are being copied.
In some cases the virtual machine can write to different memory pages / disk blocks at a higher rate than these can be copied, which will prevent the migration process from completing in a reasonable amount of time. In this case, live migration will be aborted if it is running for a long period of time. The timeout is calculated base on the size of the VMI, it's memory and the ephemeral disks that are needed to be copied. The configurable parameter completionTimeoutPerGiB, which defaults to 800s is the time for GiB of data to wait for the migration to be completed before aborting it. A VMI with 8Gib of memory will time out after 6400 seconds.
A VM Live Migration will also be aborted when it notices that copying memory doesn't make any progress. The time to wait for live migration to make progress in transferring data is configurable by the progressTimeout parameter, which defaults to 150 seconds.
KubeVirt puts some limits in place so that migrations don't overwhelm the cluster. By default, it is to only run 5 migrations in parallel with an additional limit of a maximum of 2 outbound migrations per node. Finally, every migration is limited to a bandwidth of 64MiB/s.
You can change these values in the kubevirt CR:
apiVersion: kubevirt.io/v1 kind: Kubevirt metadata: name: kubevirt namespace: kubevirt spec: configuration: migrations: parallelMigrationsPerCluster: 5 parallelOutboundMigrationsPerNode: 2 bandwidthPerMigration: 64Mi completionTimeoutPerGiB: 800 progressTimeout: 150 disableTLS: false nodeDrainTaintKey: "kubevirt.io/drain" allowAutoConverge: false ---------------------> related to: Auto-converge allowPostCopy: false -------------------------> related to: Post-copy unsafeMigrationOverride: false
Remember that most of these configurations can be overridden and fine-tuned to a specified group of VMs. For more information, please refer to the Migration Policies section below.
Migration policies provides a new way of applying migration configurations to Virtual Machines. The policies can refine Kubevirt CR's MigrationConfiguration that sets the cluster-wide migration configurations. This way, the cluster-wide settings default how the migration policy can be refined (i.e., changed, removed, or added).
Remember that migration policies are in version v1alpha1. This means that this API is not fully stable yet and that APIs may change in the future.
Currently, the MigrationPolicy spec only includes the following configurations from Kubevirt CR's MigrationConfiguration. (In the future, more configurations that aren't part of Kubevirt CR will be added):
All the above fields are optional. When omitted, the configuration will be applied as defined in KubevirtCR's MigrationConfiguration. This way, KubevirtCR will serve as a configurable set of defaults for both VMs that are not bound to any MigrationPolicy and VMs that are bound to a MigrationPolicy that does not define all fields of the configurations.
Next in the spec are the selectors defining the group of VMs to apply the policy. The options to do so are the following.
This policy applies to the VMs in namespaces that have all the required labels:
apiVersion: migrations.kubevirt.io/v1alpha1 kind: MigrationPolicy spec: selectors: namespaceSelector: hpc-workloads: true # Matches a key and a value
The policy below applies to the VMs that have all the required labels:
apiVersion: migrations.kubevirt.io/v1alpha1 kind: MigrationPolicy spec: selectors: virtualMachineInstanceSelector: workload-type: db # Matches a key and a value
/* Enable algorithms that ensure a live migration will eventually converge. * This usually means the domain will be slowed down to make sure it does * not change its memory faster than a hypervisor can transfer the changed * memory to the destination host. VIR_MIGRATE_PARAM_AUTO_CONVERGE_* * parameters can be used to tune the algorithm. * * Since: 1.2.3 */ VIR_MIGRATE_AUTO_CONVERGE = (1 << 13), ... /* Setting the VIR_MIGRATE_POSTCOPY flag tells libvirt to enable post-copy * migration. However, the migration will start normally and * virDomainMigrateStartPostCopy needs to be called to switch it into the * post-copy mode. See virDomainMigrateStartPostCopy for more details. * * Since: 1.3.3 */ VIR_MIGRATE_POSTCOPY = (1 << 15),